
Kişiselleştirilmiş CRISPR Gen Düzenleme Tedavisi
CRISPR gen düzenleme tedavisinin uygulama alanına ve bu tedaviyi mümkün kılan CRISPR-Cas9 teknolojisine dair.

Önceki yazılarımda, hem yapay zekânın kullanıldığı farklı alanlardan hem de bu teknolojinin zararlarını önlemek ve azaltmak için Avrupa Birliği Yapay Zekâ Yasası ile getirilecek olan risk temelli yaklaşımdan bahsetmiştim. Otomasyon, endüstri 4.0, dijital dönüşüm ve yapay zekâ gibi alanlar günlük yaşantımızın ve gündemin öyle içinde ki uzak kalmak mümkün değil.
Bu yazıyı yazdığım ve yayımlandığı günlerde Türkiye yerel seçim sürecinde. Birkaç gün önce bir siyasi parti lideri, belediye seçimlerinde yapay zekâdan yardım aldıklarını ifade etti.1 Tam da yazmak istediğim konuda bana güncel bir örnek vermiş oldu. Kimin söylediği, bağlamı ve ayrıntılar hiç önemli değil. Zira hangi ülkenin gündemine biraz göz atsak benzer bir haber bulmak mümkün. Kısaca ifade edecek olursak, siyasi parti tarafından çok sayıda katılımcıyla seçimde kimi aday görmek istedikleri konusunda bir anket yapılıyor. Ardından bu ses dosyaları otomatik konuşma tanıma algoritmalarıyla metne dönüştürülüyor. Bu cevaplar prompt olarak veriliyor ve bir büyük dil modeline sorular soruluyor. Model, belki de aday olmayan ancak katılımcılar tarafından sevilen, öne çıkan bir ismi öneriyor. Bunun ötesinde, anket cevaplarına göre bir şehrin sorunlarını ve aday sloganını da belirledikleri de ifade ediliyor. Bu uygulama makul mü? Adaletli mi?
Bu yazıda algoritmaların adaleti ya da adaletsizliği konusunu farklı örneklerle ele alıp, en sonunda da bu örneğe tekrar döneceğim.
Her ne kadar bugün daha karmaşık sistemlerden, büyük dil modellerinden bahsediyor olsak da bazı problemler soru-cevap formatında yazışmayı ya da yüksek çözünürlükte resimler, videolar üretmeyi gerektirmiyor. Bir başka örnek de kriminolojinin (suç bilimi) ilgilendiği şu soru: Acaba hâlihazırda suç kaydı olan bir insanın yeniden suç işleme eğilimi var mı? ABD’de ve dünyanın birçok ülkesinde üzerine suç isnat edilen bir kişinin suçlu olup olmadığına karar veren hakimlere, bir bilgisayar programının risk derecelendirmesi de sunuluyor.
2016 yılında, kâr amacı gütmeyen araştırmacı gazetecilik yapan bir kuruluş olan ProPublica bir rapor yayımladı.2 Bu rapora göre ABD’deki mahkemelerde kullanılan Ceza İnfaz Kurumu Profil Oluşturma sistemi COMPAS yazı tura atmaktan biraz doğruydu. Sistem tarafından yeniden suç işlemesi muhtemel görülen kişilerin %61’i iki yıl içinde başka yeni suçlardan tutuklanmıştı. Daha da önemlisi, sistemin genel doğruluk oranının ötesinde bir sorun daha vardı. Şiddet suçu işlemesi tahmin edilen kişilerin sadece %20’si gerçekten şiddet içeren bir suç işledi. Sistem özellikle siyahileri daha yüksek oranlarda bir hatayla suç işleyecek diye tahmin ediyordu. Bu durum beyazlarda daha düşüktü.
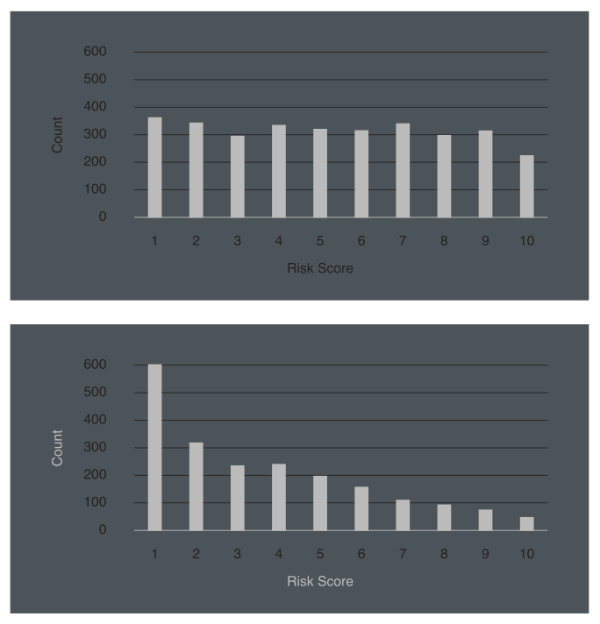
ProPublica’nın haberinin bize işaret ettiği konu, algoritmaların adaletsizliği. Her zaman, bir algoritmanın o işteki başarısı değil farklı korunan değişkenlere göre adil olması da önemli. Bu değişkenler etnik köken, cinsiyet, yaş gibi özellikleri kapsayabilir. Bu haberin ardından, makine öğrenmesi ve derin öğrenme konusunda algoritmaların yanlılığını azaltmak bir araştırma konusu olarak literatüre girdi ve yüzlerce bilimsel makale yayımlandı.
İnsanla ilgili kararlar sadece suç işleme eğilimini kapsamıyor. Bir miktar birikmiş paranız, sabit bir işiniz ve aylık geliriniz var. Bir bankaya mortgage kredisi için başvurdunuz. Bu süreçte adresiniz, iş bilgileriniz, geliriniz ve birçok kişisel bilgiyi de bankayla paylaşıyorsunuz. Benzer şekilde, veriye dayanan bir yapay zekâ sistemiyle bir kredi derecesi çıkarıyorlar ve buna göre kredi verip vermemeye karar veriyorlar.
Stanford Üniversitesi’nden Laura Blattner ve Chicago Üniversitesi’nden Scott Nelson tarafından gerçek kredi verilişi üzerinde yapılan bir çalışma, sorunun adaletsizliğin de ötesinde karmaşık olduğuna işaret ediyor.4 Azınlık konumundaki bir etnik gruba ve düşük gelirlilere önyargılı olma durumu mevcut. Veri setlerinde bu gruba ait örnek sayısı diğer gruplara nazaran çok daha az olduğu için, algoritmaların doğruluğu da önemli ölçüde düşük.
Yani algoritmaları daha adil yapmak sorunu çözmeyecek. Düşük gelirli ve azınlık grupta olanlar asla yeteri kadar çok sayıda kredi onayı alamadıkları için, algoritmaları o grupta da daha iyi çalışır hâle getirecek sayıda örnek toplamak mümkün olmayacak.
Önerdikleri çözümlerden biri, hükümetler tarafından bu sistemleri geliştiren ve kullanan kurumlarını zorlayıcı önlemler alınması. Azınlık gruplara da kredi verilmesinin ve risk değerlendirmesinin doğru toplanan veriyle yapılması performanstaki dengesizleri giderebilir.
Algoritmaların adaletsizliğini gidermek, daha dengeli veri setleri toplayarak ve öğrenme algoritmalarını farklı gruplara karşı adil karar vermelerini sağlayacak kıstaslarla eğiterek mümkün. Ancak asıl çözüm, yasa koyucuların toplumsal eşitsizlikler konusunda bilinçli olması ve bunları giderecek programlar benimsemeleri.
Birçok işyerine şirketlerin insan kaynakları uzmanlarının uzun ve ayrıntılı bir inceleme yapabileceğinden çok daha fazla başvuru yapılıyor. İnsan kaynakları da yapay zekâya dayanan araçların yoğun olarak kullanıldığı bir alan. Özgeçmişler ve başvuru mektupları isim, doğum yeri, evlilik durumu, eğitim geçmişi ve fotoğraf gibi kişisel bilgiler içeriyor. Verilen bir özgeçmişi resim ve metin olarak inceleyen büyük dil modelleri var. Bu modellerin eğitilmesini cinsiyete ve etnik gruplara göre önyargısız karar verecek hâle getirmek, başka önemli bir konu.
İnsan kaynakları uygulamaları kaçınılmaz şekilde iş dünyasında kullanılıyor olduğu için, bu soruna çözümler getiren araştırmalar da var. Örneğin yakın zamanda 24 bin özgeçmiş ve 400 bin kısa biyografi üzerinde yapılan bir araştırma, iki öğrenme görevini konu alıyor. Biri, verilen özgeçmişleri derecelendirmek. Bu, normalde insan kaynakları çalışanlarının yaptığı bir iş. Diğer öğrenme görevi ise kısa biyografilerden meslekleri tahmin etmek. Bu görevleri veri üzerinde öğrenirken hassas değişkenler olan cinsiyet ve ismi de kapsayan etnik kimlik bilgisine göre daha adil kararlar veren bir algoritma geliştirmişler. Algoritmalardan pek tabii adaletli olmalarını bekliyoruz, ancak unutmayalım ki insan kararları da yanlılıklarla dolu.5
Bu konudan bahsetmişken küçük bir öneri paylaşmadan geçmeyeyim: Siz siz olun, özgeçmişinizi hazırlarken otomatik aday takip sistemi [automated applicant tracking system, ATS] denen sistemle uyumlu olmasına özen gösterin. Bu sistem PDF formatındaki dosyalardan özgeçmişinizin anlaşılır bir metin hâlinde okunmasını sağlıyor. Sonraki aşamada, şirketlerin kullandığı yapay zekâ araçları içerik analizi yapıyor. En basitinde kilit kelimelere göre, en ileri olanlarında da dil modelleri kullanılarak bir seçim yapılıyor.
Yukarıda verdiğim birkaç örnekte amaç, insanların karar alma süreçlerinde destek olacak ya da tamamen onun yerine geçecek sistemler geliştirmek. Bunu yaparken de sadece doğru değil, bunun yanı sıra daha objektif, daha az ayrımcı ya da daha iyi sistemler hedefleniyor. Peki ama neden?
Katharina Zweig, Awkward Intelligence adlı kitabında bu konunun insana bakan iki yönünden bahsediyor.6 İlki şu: İnsanlar öyle ya da böyle karar almakta iyi değildir. Hatta son birkaç yıla kadar kararlarının iyi mi kötü mü olduğunu ölçemiyorduk. Son on yıllık araştırmalar sonucunda, algoritmik karar sistemlerinin yanlılıklarını ölçecek farklı performans ölçülerine sahibiz.
Diğer senaryo ise bir insanın gelecekten davranışını, kendisinin ya da başkalarının geçmişteki davranışlarından anlamanın mümkün olması. İnsan kaynakları örneğinden hareketle üç durum söz konusu. İlk olarak, başvuranın sadece geçmiş eğitimine ve kişilik özelliklerine bakarak şirket için uyumlu olup olmadığına karar veririz. İkinci seçenek, biraz nedensellik ilkesini kullanarak “Açtığımız bu pozisyon için bu niteliklere sahip birisi acaba ne yapardı?” sorusuna cevap aramak. Üçüncü seçenek ise var olan tüm başvuruları sıralamak ya da gruplandırmak. Gayet, algoritmalara verilebilecek bir görev gibi görünüyor.
Hangi kritere göre ilerlerseniz ilerleyin, o kişi daha önce o şirkette çalışmadı. Beklenen rolün gereklerini yerine getirebilecek mi? Bu, yüksek riskli bir tahmin. Hatta nedensel öğrenmeye de ihtiyaç var. Örneğin Avusturya’daki iş bulma kurumu işsiz ve iş arayan insanları, iyi iş bulma şansına sahip, iş bulma şansı düşük ve diğerleri olmak üzere üç gruba ayıran bir sistemi test etmiş.
Kullanılan istatistiksel model, iş bulma kurumunu ziyaret sayısını önemli bir nitelik olarak kabul etmiş. Halbuki Avusturya özellikle kış turizmiyle meşhur ve mevsimlik çalışan işçilerin ziyaret sayısı daha fazla; yani ziyaret sayısını kullanmak bir gruba öncelik sağlamış ama bu, işsizliği azaltacak bir etki yapmıyor. Bu yüzden, algoritmaların adaleti ve şeffaflığının da ötesinde sosyal sürdürülebilirlik için bazı kurallara ihtiyaç var. Bu kurallar algoritma geliştiricisi kadar kullanıcıya da sorumluluklar yüklemeli. Avusturya örneğinde uyguladıkları kurallar şunlar: Kararları her zaman insan verecek ama sistemi ikinci tavsiye olarak tutacak. Kullanıldıkça sürekli yeni veri üzerinde sistemi kullanmanın işsizliği düşürmede etkisi ölçülecek. Son olarak da yılda bir algoritma yeni veri de eklenerek yeniden eğitilecek.
Algoritmaları kullanmak ya da kullanmamak, o karar almadaki potansiyel sosyal risklerle ilgili. Daha önceki bir yazıda ele aldığım nedensel öğrenme ise işin diğer bir boyutu. Gerçekten, eğer elimizde var olan değişkenlerle cevap aradığımız soru arasında gözlemlere bakmak yerine, merdivende bir adım daha çıkıp müdahale ve karşı olgusal muhakemeye dayalı elde ettiğimiz bir model kullanabiliriz. Maalesef ki işin ucunda ciddi bir maddi çıkar elde etmek olunca, kimse algoritmaların adaletine öncelik vermiyor.
Yeniden suç işleme eğilimi, kredi derecelendirme ve iş başvuruları gibi farklı örneklerden sonra başladığımız noktaya, seçimlere dönelim. Anladığım kadarıyla, kastedilen sadece telefon görüşmeleri yoluyla yapılan nitel anketlerin ses kayıtlarını metne çevirmek. Eğer anket yapılan kişiler çok farklı, yerel bir ağızla konuşmuyorsa bu gayet mümkün. Hatta doğal dil işleme yöntemleriyle, katılımcılar içinde en popüler olan görüşleri çıkarmak, bunların istatistiğini yapmak da mümkün. Ancak bir büyük dil modeline anket verisi ya da şehrin sorunları hakkında fikir sormak biraz fazla geliyor. Sanki bir gerilim filmlerinde ne olduğu belirsiz bir düğmeye basmak ya da bir bomba patlamadan kırmızı kabloyu kesmek gibi.
Bir fabrikada üretim bandında defolu ürünleri bulmak, bir ambardan sipariş edilen bir şeyi alıp kargolamak, pek tabii yapa zekâ desteğiyle mümkün olabilir. Bu teknolojinin çığır açtığı onlarca alan var. İçinde insan olan kararlarda biraz şüpheci olmalı. Algoritmik karar vermede, konunun sadece yazılım mühendisleri ve veri bilimciler de değil hem kullanıcıları hem de tüm toplumu ilgilendiren yönleri var. Her zaman algoritmaların adaletini, hesap verebilirliğini, şeffaflığını ve etik boyutlarını düşünmeli.
{fold içindeki görsel: Bir sanatçının yapay zekâ çizimi. Yapay zekâ sistemlerinin temelinde hesap verebilirliğin olması gerektiğini temsil eden bu görüntü Champ Panupong Techawongthawonas tarafından oluşturulmuştur. Kaynak: Pexels.} 1. Mustafa Bildircin, “CHP’de Yapay Zekâ Adayı”, Birgün gazetesi, 16 Şubat 2024.
2. Aynı yerde.
3. Julia Angwin, Jeff Larson, Surya Mattu ve Lauren Kirchner, “Machine Bias There’s software used across the country to predict future criminals. And it’s biased against blacks”, ProPublica, 23 Mayıs 2016. [https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing]
4. Will Douglas Heaven, “Bias isn’t the only problem with credit scores—and no, AI can’t help”, MIT Technology Review, 17 Haziran 2021.
5. Leo Hemamou ve William Coleman, “Delivering Fairness in Human Resources AI: Mutual Information to the Rescue”, Proceedings of the 2nd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 12th International Joint Conference on Natural Language Processing içinde, 2022.
6. Katharina A. Zweig, “Awkward Intelligence: Where AI Goes Wrong, why it Matters, and what We Can Do about it”, MIT Press, 2022.













