
Kişiselleştirilmiş CRISPR Gen Düzenleme Tedavisi
CRISPR gen düzenleme tedavisinin uygulama alanına ve bu tedaviyi mümkün kılan CRISPR-Cas9 teknolojisine dair.

Bilim insanları, yazının en eski formunun yaklaşık 5500 yıl önce Mezopotamya’da, bugünkü Irak sınırlarında kalan bölgede görüldüğü konusunda hemfikir. İlk örnekleri resimli ve simgesel anlatılardan oluşan yazı, bugün kullandığımız gibi karmaşık ve sistemli bir yapıya Sümerceyle ulaşarak çok sonraları kuzey Mezopotamya’da Asurcaya dönüştü. Çoğunlukla bu yazılar cuneiform denen tabletlere yazıldı. Cuneo, Latincede çivi anlamına geliyor. Küçük cuneiform tabletler kilden yapılmış, yazı çiviyle yazılmış, sonra güneşte ya da fırında kurutulmuş. Farklı zamanlarda, farklı coğrafyalarda birbirinden farklı yazı teknikleri ve alfabeler kullanıldı. Çocukluğumda arkeoloji müzelerinde bu tabletleri ilk gördüğüm zamandan bu yana aklımı kurcalayan bir soru var: Nasıl oluyor da bugün binlerce yıl öncesinden kalan ve son iki yüz yıla yakın süredir keşfettiğimiz dillerde yazılmış metinleri okuyup anlayabiliyoruz?
Aklımda bu soruyla, “Hangi kayıp diller, nasıl çözümlenir?”in yanıtlarını arama peşindeyim. Çoğunlukla geçtiğimiz yüzyılın başında, geleneksel yollarla bu çözümlemeler nasıl yapıldı? Bunun yanında, son yıllarda bu alanda yapay zekâ ve matematiksel yöntemler kullanılarak yapılan ilgi çekici çalışmalar var. Acaba, kayıp dilleri çözümlemede modern teknolojiler ne gibi fırsatlar sunabilir?
Dilbilgisi kurallarını, alfabesini, hatta alfabesindeki harflerin, sözcüklerin anlamlarını ve ses bilgisini bilmediğimiz diller nasıl keşfedilmiş olabilir? Aslında, bu hikâye biraz kripto analiz uzmanlarının yaptığı gizli, kodlanmış mesajları çözümlemeye benziyor. Bilgisayar bilimlerinin kurucusu sayılan kriptolog Alan Turing’in İkinci Dünya Savaşı sırasında Alman bir denizaltıda mesajları şifreleme ve tekrar çözümlemede kullandıkları Enigma cihazının şifresini kırması gibi biraz. En büyük fark, bu dillerle ilgili kaynakların çok sınırlı olması, yani elimizde çok az metin olması. Hatta bazılarının etkileştikleri dilleri ve kültürleri bilmememiz, işi daha da zorlaştırıyor.
Ölü dillerde bulunan yazıtların, tabletlerin şifresini sadece arkeologlar ya da filologların çözdüğünü sanıyorsanız yanılıyorsunuz. Kayıp diller çok farklı alanlardan insanların ilgisini çekti. Mesela, 1965 yılında Nobel Fizik Ödülü alan ünlü kuramsal fizikçi Richard Feynman, Maya hiyerogliflerindeki sayıları ve Maya takvimini eğlenceli ve heyecan verici bulduğunu söyledi ve derslerinde bundan bahsetti. Tabii her keşifte olduğu gibi diller konusunda da şans faktörü var. Maya yazısının çözümlenmesinde çığır açan kişiler, Feynman değil, başkaları oldu.
Maya yazısından söz etmişken, bu dilde yazılmış, günümüze ulaşan sadece dört kitap olduğunu hatırlamakta fayda var. 16. yüzyılda kolonileştirme esnasında İspanyol Fransisken misyoner Diego de Landa, Mayalara ait tüm kitapları yaktı. Bu kitaplara “kodeks” adı veriliyor; incir ağacının kabuğuna yazılmışlar ve katlanmış bir gezi rehberi büyüklüğündeler. Dresden, Madrid, Paris ve Grolier kodeksleri. İlk üçü, kolonyalistler tarafından götürüldükleri ve muhafaza edildikleri şehirlerle isimlendirildi. Sonuncusu, ilk kez 1960’larda ortaya çıktı ve New York’taki Grolier Kulübü’nde bir sergide görüldü. Doğruluğu ise sadece birkaç yıl önce kanıtlandı. Tüm hiyeroglifleri yakan ve Mayalılara işkence eden din adamı Landa, ironik bir şekilde kalan kitapların çözümlenmesinde kullanılacak notlar tuttu. Relación de las cosas de Yucatán adındaki bu kitap Madrid’de bir kütüphanede unutulmuştu. Ta ki Guatemala’da çalışmış Fransız bir rahip, Abbé Charles-Étienne Brasseur de Bourbourg Mayalara ilgi duymaya başlayıp Relación’u keşfedip 1864’te tıpkıbasımını yapana kadar. Düşününce öyle heyecan verici ki, kim bilir belki şimdi de bir kütüphanede yüzlerce yıldır unutulmuş, bilinmeyen ya da az bilinen uygarlıklara dair ne kitaplar vardır.

Biraz da Akdeniz’e Dönelim: Michael Ventris’in Linear B’yi Keşfi
Homeros dahi Odysseia’da bahseder Kral Minos’un hüküm sürdüğü Girit’teki Knossos şehrinden. Ancak Knossos daha yakın bir tarihte, 1878’de keşfedildi. Kazılar 1900’den itibaren İngiliz arkeolog Sir Arthur John Evans başkanlığında yapıldı ve tam otuz beş sene sürdü. Bu esnada Evans kil tabletler buldu. Bazıları Mısırdakilere pek de benzemeyen hiyeroglifler ve Linear Sınıf A ve Sınıf B diye adlandırdığı iki farklı yazı. Linear A, adanın güneyindeki başka bir kazıya ait. Girit’te çalıştığı tüm bu süre boyunca, Evans bu tabletlerin şifresini kendi çözmek istediği için bilim dünyasıyla paylaşmakta isteksiz davrandı. Sayıca daha fazla oldukları için de MÖ 1400-1200’lerden kalan Linear B’ye yoğunlaştı. 1941’deki ölümüne kadar da pek ilerleme kaydedemedi. Evans, Linear B’nin Yunancadan bağımsız, kendine özgü bir dil olduğuna takıldı. Hatta Linear B’ye çok benzeyen, Yunancayla eş metinleri de olan Kıbrıs yazıları üzerinde de çalıştı. Halbuki düşündüğünün aksine, Linear B Yunan alfabesinden de eski ve Miken Yunancasında yazılmıştı.

Evans’ın ölümü ve İkinci Dünya Savaşı yüzünden bir süre ulaşılamaz olan kil tabletler üzerinde, Amerikalı arkeologlar Alice E. Kober ve Emmett Bennett Jr. çalışmaya başladı. Aslında Linear B’nin şifresinin çözülmesi yolunda önemli taşları Kober ve Bennett döşedi. Kober’in 1948 yılında Minos yazıları hakkındaki makalesinde yazdığı gibi, aslında bilinmeyen bir dil ve bilinmeyen bir yazı sistemi çözülemez. Bir dili çözümlemek isteyen filologların önünde üç bilinmeyen var: dil, yazı ve anlam. İşte bir şekilde bunlar arasında bağlantı kurmaları ya dilin ne olduğunu bilmeleri ya da gliflerin ses karşılıklarını keşfetmeleri gerek. Böylelikle de denklemdeki bilinmeyenleri azaltmak. Kober, bir klasikçi olduğundan, isim ve fiillerin çekimlerinin nasıl değiştiğini inceledi. Aslında en önemli keşfi, çekim tabloları yaparak bir kelimenin sonunda ya da başında cinsiyet ve sayıya göre değişiklikler olduğuna ulaşmasıydı. Mesela Latincede ismin hâlleri nominativ (yalın hâl), akkusativ (-i hâli), genitiv (iyelik eki), dativ (-e hâli) (örneğin dominus, dominum, domini, domino) ya da kişilere göre fiil çekimi (amo, amas, amat, amamus, amatis, amant). Ayrıca bu çekimler Linear B’de daha fazla ve Linear A’dan farklıydı. Benzer örüntülerin dilin içinde tekrar tekrar görülmesi de dilin çözümlenebilmesi için önemli bir ipucu. Öte yandan Linear A sadece Girit’te ve az sayıda, ama Linear B’den Yunanistan anakarasında, Pilos’ta (Navarin) çok sayıda bulunduğu için Linear B’ye yoğunlaştılar. Bennett, Linear A ve B’nin nümerik sistemlerinin benzer olduğunu, ancak Linear A’da 1/2, 2/3 gibi kesirli sayılar varken Linear B’de kesirler için ayrı kelimeler olduğunu keşfetti. Bennett ise aynı harflerin farklı versiyonlarının olduğunu gösterip bunların istatistiksel dağılımını inceledi.
Tam da bu noktada, Linear B üzerine çalışan en sıra dışı isme geldik: Michael Ventris. Ventris, ne arkeoloji eğitimi almış, ne bu işi mesleği olarak yapan biri, ne de Evans gibi zengin. Savaş sırasında Kraliyet Hava Kuvvetleri’ne katıldı ve savaş esnasında Almanya’nın bombalanmasında hava mürettebatı olarak görev aldı. Sonrasında mimarlık okudu, ama diller hep ilgisini çekti. Çocukluğundan beri adeta bir poliglot olan Ventris, birkaç Avrupa dilini öğrendi. Daha on dört yaşındayken Londra’da bir kutlama sırasında Evans’ın verdiği derse katıldı ve Linear B’yi çözmek istediğini ta o zaman ifade etti. Öyle ki bundan dört yıl sonra American Journal of Archaeology’de bugün doğru olmadığını bildiğimiz Linear B ile Etrüskçe arasında bağlantı kurduğu makalesini yazdı.
Ventris sonrasında da durmak bilmedi. Ana aracı hece tablolarıydı. Tablonun satırları doğrudan ne olduğunu tahmin etmeden sessiz harfleri, sütunları ise onunla birlikte görülen sesli harfleri sıralıyordu. Bu tablolardan sonra önünde dilbilgisi, bağlam ve yazım vardı. Özellikle dilbilgisi, ismin hâllerine ve cinsiyete göre değişen farklı çekim örüntüleri, probleme ayrı bir zorluk katıyordu. Pilos tabletlerinde çıkarılan bağlam analizi beş binin üzerinde işaret grubu ortaya koymuştu. Şimdi internet çağında yaşıyor ve binlerce kilometre ötedeki insanlarla evimizden video görüşmesi yapıp ortak çalışma yapabiliyoruz. Ventris işte bu tabloları ve ulaştığı sonuçları çalışma notları hâline getirip bu konuda çalışan onlarca araştırmacıya postayla gönderiyordu. Böylece onların yorumunu ve eleştirisini de alma şansı oluyordu. Ventris’i başarıya götüren şeylerden biri tablolarındaki hece bağlantılarını incelerken, klasik metinlerde isimleri bilinen ve aynı zamanda tabletlerde de çok tekrar eden Girit’teki yer isimlerine yoğunlaşmasıydı. Çözüme yaklaşması ise Yunancayla bağlantılı olduğunu düşünmesiyle oldu. 1951-52 yılları arasında gönderdiği yirminci notun başlığı şuydu: “Knossos tabletleri Yunanca mı yazıldı?” Bu nota başlar ve bitirirken spekülatif olduğu için özür diliyordu. Kober ve Bennett’in ulaştığı gibi Linear A ve B farklı dillerse, Linear A anakarada farklı yerlerde ve Girit’te ise Knossos’ta bulunmuşsa, pek de âlâ Yunanca olabilirdi. Linear A ise Helenik dönem öncesi başka bir dil.
İki yoğun yılın sonunda, Ventris 1952’de BBC radyoda bir programda Linear B’yi çözdüğünü söyledi ve programı dinleyen John Chadwick kendisine ulaştı. Savaş sırasında Bletchley Park’taki şifre çözme çalışmalarına katılmış olan Chadwick, Cambridge Üniversitesi’nden bir klasikçi ve filolog. Dört yıl boyunca Ventris’in keşfi üzerine çalışıp bunu bir kitap hâline getirdiler. Ne yazık ki Ventris kitabın çıkmasına kısa bir süre kala bir trafik kazasında hayatını kaybetti.

Ventris’in Linear B çözümlemesinde oluşturduğu ve notlarında paylaştığı tablolardan örneklere Maurice Pope’un The Story of Decipherment adlı kitabından ulaştım.
Ve Bugün: Yapay Zekâ ve Hesaplamalı Bilimler Nasıl Yardım Edebilir?
Özellikle son on yılda yapay zekâ, daha doğrusu yapay zekânın makine öğrenmesi ve derin öğrenme adı verilen alt dalı inanılmaz gelişmeler gösterdi. Mesela bir internet sitesini ya da yazdığımız bir yazıyı neredeyse çok az hatayla başka bir dile çevirebiliyoruz. Örneğin Türkçeden İngilizceye makine çevirisi sistemlerini eğitebilecek iki dilde, belki koca bir kütüphane bulmak mümkün. Antik Yunanca ve Linear B arasında böyle bir veri maalesef yok. Üstüne, derin öğrenme yöntemleri büyük miktarda veriye ihtiyaç duyuyor ve elimizdeki tüm metinler bugünkü dillerdekilere kıyasla çok küçük.
Makine çevirisinin ardında yatan fikir ise filologların elle yaptığı bağlam analizinin biraz ötesinde: Bir dil içinde, sözcüklerin birbiriyle ne sıklıkta kullandığını incelemek ve o dildeki tüm sözcükleri ifade edecek bir değişkenler kümesi tanımlamak. Böylelikle, mesela her kelimenin vektörel ifadeleriyle “kral-erkek+kadın” gibi bir matematiksel işlem yapalım ve bize “kraliçe” kelimesini versin. Aslında burada bizi çeviriye götürecek şey, aynı ifadenin farklı dillerde aynı vektörel değere sahip olmasını sağlamak. Bire bir karşılıklı bir metin olmadığı için, mevcut teknoloji ölü dilleri çevirmekte tıkanıyor gibi.
Massachusetts Teknoloji Enstitüsü’nden Jiaming Luo, Regina Barzilay ve Google’dan Yuan Cao tarafından yayınlanan bir çalışma, Linear B’den Yunancaya makine çevirisi yapılabileceğini gösterdi. Yaptıkları şey dillerin sadece belirli şekillerde değişebileceğini kabul etmek. Örneğin kullanılan harfler, harf dizimi ya da kelimeler. Böylece iki dildeki aynı kökten kelimeleri (cognate) belirleyip onlar arasında çeviri yapıyorlar. Linear B’den Yunancaya makine çevirisinin ilk örneği olan bu çalışma, aynı kökten kelimeleri %67,3 doğrulukla Yunancaya çeviriyor. Hatta kullandıkları yöntem Akdeniz’in başka eski uygarlıklarından ve en eski alfabelerinden Ugaritçe ile İbranice arasında da benzer doğrulukla çalışıyor. Ugaritçeye dair kalıntılar bugün Suriye sınırları içindeki Ras Şamra bölgesinde bulundu ve MÖ yaklaşık 1300 civarına tarihleniyor. Linear B ve Yunanca ilişkisine benzer şekilde, Ugaritçe çiviyazısıyla ancak otuz civarı simgeyi harf işlevinde kullandı. Dil ise Sami dil ailesinden ve İbraniceyle önemli bir benzerlik gösteriyor.
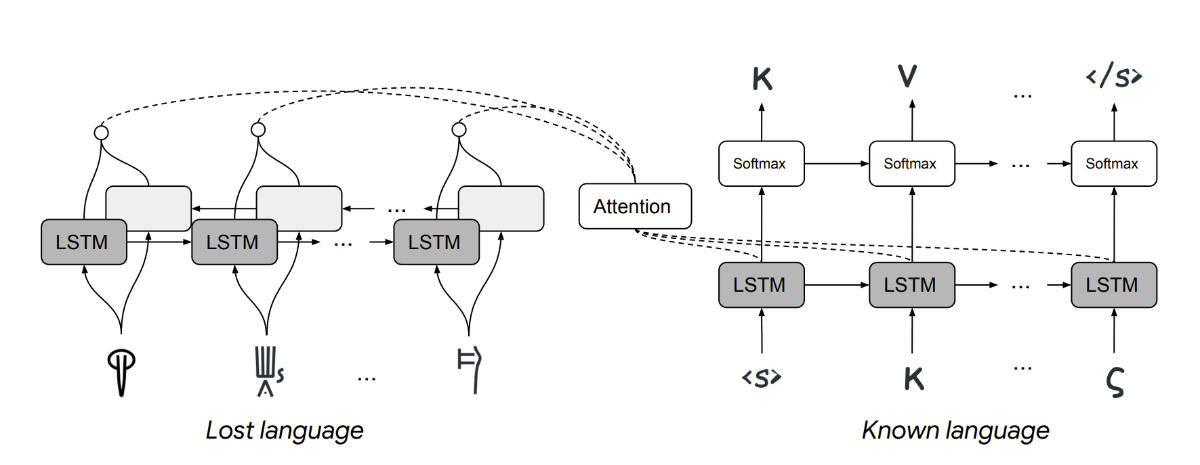

Sonuç olarak yapay zekâ, istatistiktik ve veri biliminin çığır açtığı alanlardan biri de doğal dil işleme uygulamaları. Hâlihazırda makine çevirisi Türkçe için bile çok kolay sayılmaz. 2018 yılında Google Çeviri’nin “O bir doktor” cümlesini erkek, “O bir hemşire” cümlesini kadın olarak çevirmesi olay yaratmıştı. Bunun sebebi şüphesiz Türkçe üçüncü tekil kişinin cinsiyetsiz olması ve makine çevirisi sistemlerinin mevcut metinlerdeki önyargıyı yansıtması. Düşük kaynaklı dillerde bu teknolojilerin daha doğru sonuçlar vermesi biraz daha zaman alacak gibi. Hele ki Linear A, Indus, Proto-Elamit yazıtları ve onlarca çözümlenmemiş ölü dil için bu çok daha zor.
Digital Humanities alanındaki gelişmeler ve disiplinlerarası işbirliğiyle dilbilimi, arkeoloji, mimari gibi farklı alanlarda çalışan araştırmacılara çözümler sunuyor. Belli mi olur, belki yakında yeni teknolojilerin sadece bugünkü yaşantımızı değiştirmesi ve dönüştürmesi bir yana, geçmişin bilinmeyenlerine ulaşmada da etkili olur.
Kaynakça:
Andrew Robinson, Lost Languages: The Enigma of the World’s Undeciphered Scripts (Thames & Hudson, 2009).
Jiaming Luo, Yuan Cao ve Regina Barzilay, “Neural Decipherment via Minimum-Cost Flow: From Ugaritic to Linear B.”, Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019.
John Chadwick, The Decipherment of Linear B (Cambridge University Press, 1990).
Maurice Pope, The Story of Decipherment: From Egyptian Hieroglyphs to Maya Script: From Egyptian Hieroglyphs to Maya Script (Thames & Hudson, 1999).














{kind=link}
{kind=link}