
Kişiselleştirilmiş CRISPR Gen Düzenleme Tedavisi
CRISPR gen düzenleme tedavisinin uygulama alanına ve bu tedaviyi mümkün kılan CRISPR-Cas9 teknolojisine dair.

Daha önce, arkeologlar ve filologların kayıp dilleri nasıl çözümlediklerini tarihi örnekler ve yapay zekânın sunduğu fırsatlarla birlikte ele almıştım. Paleografi –Yunanca palaiós [eski] ve grapheía [yazım] bilimi– farklı yazı türlerinin okunup anlaşılması ve tarihi bağlamda anlam ve önemlerinin çözülmesiyle ilgileniyor. Uzmanlar birkaç santimetre büyüklüğünde bu tabletleri anlamak için aylarca çalışıyor. Hakkında çok şey bildiğimiz ölü dillerde yazılmış tarihi belgeleri ya da çiviyazısı kil tabletleri anlamak dahi çok zor. İşte, otomatik karakter tanıma ve dil işleme teknolojileri, araştırmacıların zaman alan ve monoton işlerden kurtulup, metinler üzerinde daha ileri seviyede, sosyal ve kültürel incelemeler yapmasına imkân sağlıyor. Bu yazıda önce dünyanın farklı yerlerinde, kil tabletlerin dijitalleştirilmesiyle ilgili çalışmalara, ardından da kullanılan yapay zekâ yöntemlerine göz atalım.
Çiviyazısı kil tabletler deyince, farklı kazı çalışmalarından ulaşılmış, farklı dillerde on binlerce tabletten bahsediyoruz. Bu tabletlerin modern dillere çevrilmesi, tarihi ve sosyal yönleriyle ele alınıp anlaşılması çok zor. İşin insan emeği kısmı öyle ağır ki, bazı metinlerin incelenmesi, anlaşılması belki bir insan ömrünü bile aşıyor. Ayrıca günümüzde bu konularda çalışan herhangi bir araştırma grubu dünyanın farklı yerlerinde o konu üzerinde çalışan başka gruplarla ortak çalışmalar yapıyor. Bu yüzden, ortak, sistematik çalışma araçlarının geliştirilmesi, her şeyden de önce metinlerin dijitalleştirilmesi önem taşıyor.
Chicago Üniversitesi dünyada arkeoloji ve filoloji alanında en önemli enstitülere ve araştırma gruplarına sahip üniversitelerden biri. Kazı çalışmaları onlarca yıl sürdüğü için ilk kazıları yapan üniversiteler o kültürler üzerine yapılan sonraki keşif ve araştırmalarda da başı çekiyor. Antik İran’ın başkenti Persepolis’in ilk kazıları da Chicago Üniversitesi’nin Şark Enstitüsü tarafından görevlendirilen Alman arkeolog Ernst Emil Herzfeld tarafından 1931’de başlatılmış. Sadece bu enstitünün arşivinde bugüne kadar ulaşılmış on binlerce tablet var.

Peki, bu tabletlerdeki işaretleri nasıl otomatik olarak tanıyabiliriz? Yapay zekânın bir alt dalı olan bilgisayarlı görü [computer vision] adı verilen alan, bu problemle de ilgileniyor. Buna otomatik karakter tanıma deniyor. Günümüzde birçok tarayıcı dijitalleştirildiği metinleri aynı zamanda yazıya çeviriyor. Aynı işi Chicago Üniversitesi’nden bilgisayar bilimleri profesörü Sanjay Krishnan, Elam dilinde derin öğrenme modellerini kullanarak yapmış.1 Bunun için yaklaşık 6000 tablet üzerinde, kutucuklar içinde hangi işaret olduğu etiketlenmiş ve böyle büyük bir eğitim seti oluşturulmuş. Bugün otonom araçlarda ya da cep telefonumuzdaki basit uygulamalarda kullanılan derin öğrenme modellerinden biri, bu tabletlerin transkripsiyonunda yüzde seksenin üzerinde doğruluk sağlamış.2 Sadece bu performans dahi paleografların işini epey kolaylaştıracak gibi görünüyor.
Bilgisayarlı görünün bir adım sonrasında doğal dil işleme problemlerine sıra geliyor. Tüm dillerde art arda gelen işaretlerin (hatta kelimelerin ya da kavramların) belli bir istatistiksel dağılımı var. Belki görüntü işleme bir karakteri doğru tanımamış olabilir, ancak doğal dil işleme modelleri burada her karakter için en yüksek ihtimalle tahmin edilen işareti bir dizi içinde öğreniyor ve aralarından dilin yapısına en uygun olanı seçiyor.
Her ne kadar konuya bilgisayar bilimleri yönünden bakanlar için veri biliminin ve algoritmaların kullanılması heyecan verici gelse de bazen çok daha basit görünen teknolojiler alan uzmanlarına büyük kolaylık sağlayabiliyor. Chicago Üniversitesi tarafından geliştirilen OCHRE yazılımı, farklı araştırmacıların aynı veriye erişebilmelerine ve bir arayüz aracılığıyla resim ve yazıları düzenleyebilmelerine imkân veriyor. Böylece çok sayıda metin, farklı araştırmacılar tarafından aynı standartlarda etiketlenip tasnif edilebiliyor. Yazıların fotoğrafları ideal şartlar altında çekilmiş olmayabilir. Basit filtrelerle kullanıcılar tabletlerin resimlerini daha kolay okunabilir hâle getirebiliyor.
Gün geçtikçe daha fazla yazılı eser dijital ortama aktarılıyor. Benzer şekilde, dünyanın farklı yerlerindeki araştırma grupları çiviyazısı tabletleri dijitalleştirmeye devam ediyor. Geçtiğimiz şubat ayında Ludwig Maximilian Münih Üniversitesi’nden Eski Yakın Doğu Edebiyatı profesörü Dr. Enrique Jiménez ve ekibi daha önce yayınlanmamış 30.000 satır Akadca bir metnin erişime açıldığını duyurdu.3 Bu büyüklükte bir metnin transkripsiyonunda yapay zekâ kullanılmış. Erişime açtıkları bu metin, Babil yaratılış miti ve Gılgamış destanının tam metnini de içeriyor.
Ludwig Maximilian Münih Üniversitesi’nin Elektronik Babil Edebiyatı (eBL) koleksiyonunun ekran görüntüsü, kaynak: eBL / Corpus
Ben de “Bu ölçekteki bir transkripsiyonun arkasında ne var?” ve “Acaba hangi yöntemleri kullanmışlar?” diye merak ettim. Birkaç yıl önce, Dr. Enrique Jiménez’in de eş yazar olduğu bir makalede kullandıkları yöntemleri biraz açıklamışlar. Şimdi biraz bunun detaylarına bakalım.

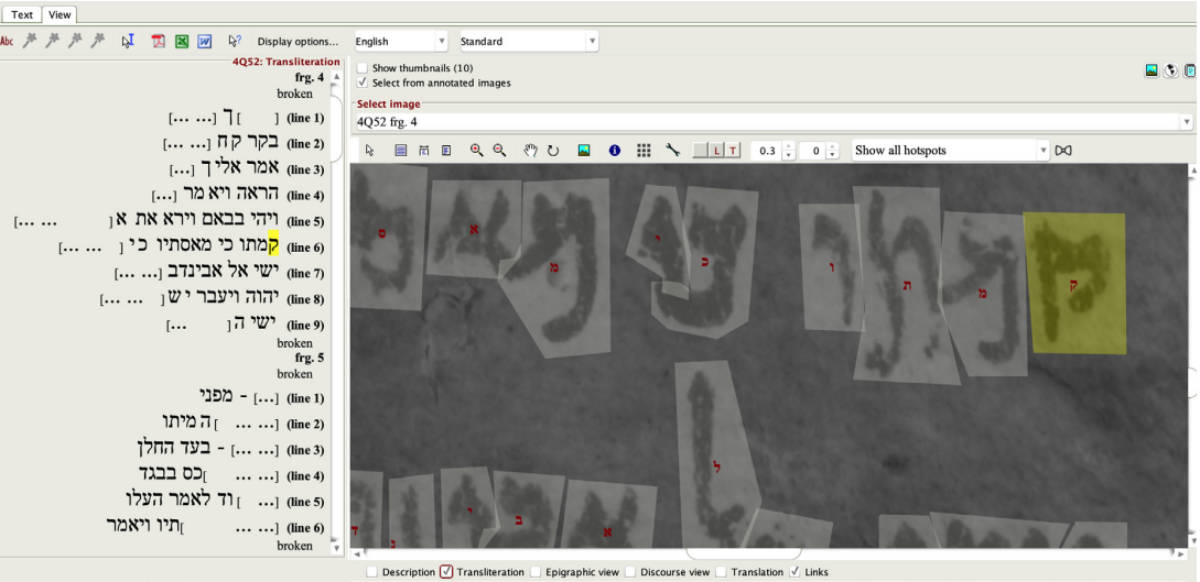
Şekilde görülen tablet, Yale Üniversitesi’nin arşivinden. Apqu şehrinde (bugünkü Musul yakınlarında Tell Abu Marya arkeolojik alanında) Asur kralı II. Aşurnasirpal’in sarayından çıkarılmış. Alışılmıştan farklı olarak tabletlerde kil yerine altın ve gümüş kullanılmış. Böyle bir metni sağ tarafta görüldüğü gibi standart karakterlere dönüştürme işlemine transliterasyon deniyor. Bu makalede transliterasyon işlemi istatistiksel ve derin öğrenmeye dayalı öğrenme yöntemleriyle ele alınmış.
Dijital teknolojiler kullanılarak böyle tabletler üzerinde üç aşamadan oluşan bir işlem uygulanıyor. İlk aşama “glif” olarak da adlandırılan bu işaretlerin, bu tabletlerin iki ya da üç boyutlu resimleri üzerinde otomatik olarak tanımlanması. Bu aşama resimler üzerinde ve bilgisayarlı görüyle çözülen bir problem. İkinci aşama bu işaretlerin transliterasyonu ve parçalara ayrılması. Son aşama da bugünkü dillere otomatik çeviri ve bunların insan yardımıyla doğrulanması. Akadca için, hatta başka dillerde de bu ikinci ve üçüncü aşamayı zorlaştıran, gliflerin kendinden önceki ve sonraki gliflere bağlı olarak temsil ettikleri anlam ile kelimenin ve okunuşlarının değişmesi. İkinci aşama, bir ya da birkaç gliften oluşan dizileri anlamlı kelime parçacıklarına bölüyor. Böylece metinler bugün kullandığımız dillere çevrilmiş oluyor.
Transliterasyon ya da çeviriyi yapan hesaplamalı yöntemler, sadece tek bir karakteri değil, sıralı çok sayıda karakterin birbiriyle ilişkisini anlayıp çözümleyebilecek yeterlilikte. Çoğunlukla bahsettiğimiz yazılar ise çiviyazıları ve kil üzerine yazılmış. Ya zaman içinde ya da çıkarıldıkları arkeolojik kazılarda zarar görmüş olmaları muhtemel. Peki ya arada eksik glifler varsa?
Yukarıdaki şekil, zarar görmüş kil bir tablete ait. Yanında transliterasyonunu görüyoruz, ancak eksik glifler var. 2021 yılında Kudüs İbrani Üniversitesi’nden Koren Lazar ve arkadaşlarının yayımladığı makale, Akadca tabletlerde eksik glifleri tamamlama üzerine. Kullandıkları yöntem son günler hepimizin duyduğu büyük dil modellerinden biri olan Bidirectional Encoder Representations from Transformers (BERT). BERT de GPT modeline benziyor, dikkat modelleri içeriyor ve denetimsiz öğrenmeyle eğitiliyor. İki model de soru cevaplama, metin özetleme, makine çevirisi gibi problemlerde kullanılabiliyor.
Akadca veri üzerinde BERT modeli maskeli şekilde eğitiliyor; yani sadece kırılmış ve eksik parçaları olan metinler değil, sağlam olanların üstünde rastgele glifler maskelenerek BERT modeli bu eksikleri tamamlamak için eğitiliyor. Hatta önce Wikipedia’da en fazla içeriğe sahip 104 dil üzerinde eğitilip sonra Akadca veri üzerinde transfer öğrenmesi gerçekleştirildiğinde daha iyi sonuç veriyor.
Her ne kadar Wikipedia’daki içeriklerin ve modern dillerin Akadcadan farklı olacağını düşünsek de bu 104 dil üzerinde eğitilmiş olan model, Akadca tabletlerdeki eksikleri tamamlamayı çok daha iyi bir performansla başarıyor. Hatta gliflerin transliterasyonlarına ek olarak İngilizce çevirilerini kullanmak da fayda sağlamış. Akadca bir dönemin lingua franca’sı. Mesela MÖ 1269’daki Kadeş Antlaşması gibi birçok resmî belgenin orijinali Akadca yazılmış. Hatta dilin geçmişi daha da eskiye, MÖ 2500’lere uzanıyor. Birçoğu görece çok yeni olan modern dillerde eğitilmiş bir dikkat modelinin Akadca metinlerde eksikleri tamamlayabilmesi çok heyecanlandırıcı. Belki uzak sandığımız diller arasında da pek fazla benzerlik var ve biz henüz bilmiyoruz.
Bu yazıda, güncel teknolojilerin çiviyazısı kil tabletleri dijitalleştirmede nasıl kullanılabileceğini ele aldık. Belki en ilgi çekici olan, hâlâ popüler olan GPT/ChatGPT, Bard gibi büyük dil modellerinin benzerlerinin, kaynak bakımından sınırlı antik dillerde dahi güzel sonuçlar vermesi. Böyle amaçlarla kullanılmaları, kültür mirasımızın dijital dünyaya aktarılması, korunması ve daha iyi anlaşılabilmesi için büyük fırsatlar sunuyor.
1. Ancient Language Processing: Teaching Computers to Read Cuneiform Tablets, UChicago CS News, 13 Şubat 2020.
2. DeepScribe projesinde izlenen yöntemi detaylı şekilde incelemek isteyenler videolardan yararlanabilir.
3. Playing with the source of world literature, Ludwig Maximilian University of Munich, 20 Ocak 2023.














